Model Interface Protocol
MIP is sheet music for interfaces.
Today's AI either writes long paragraphs of text or thousands of lines of code that have to compile and bundle before you see anything. Both are slow, expensive, and brittle.
A composer doesn't ship an orchestra with every song — they ship the score, and any orchestra that can read it plays it back. MIP is the score for interfaces. A small, structured description of what should be on screen. The AI writes the score; your computer plays it instantly as a real, interactive interface.
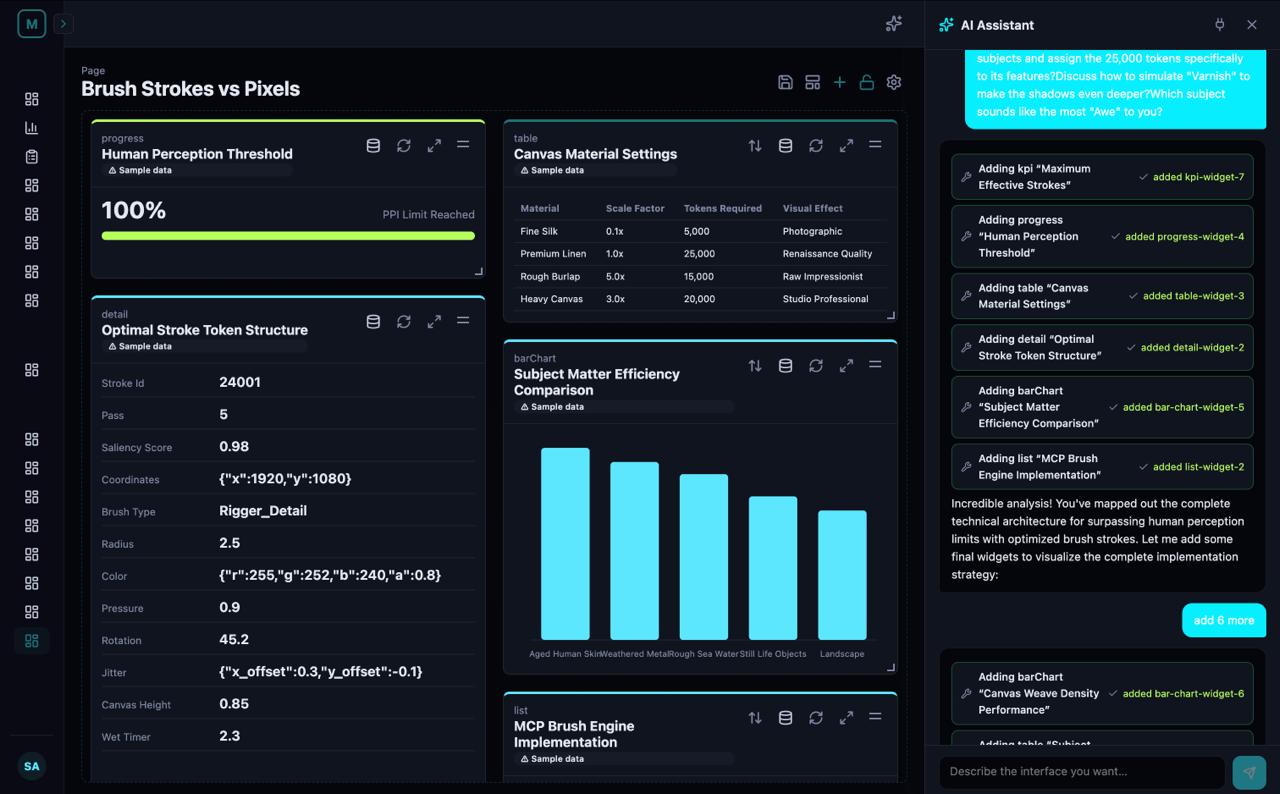
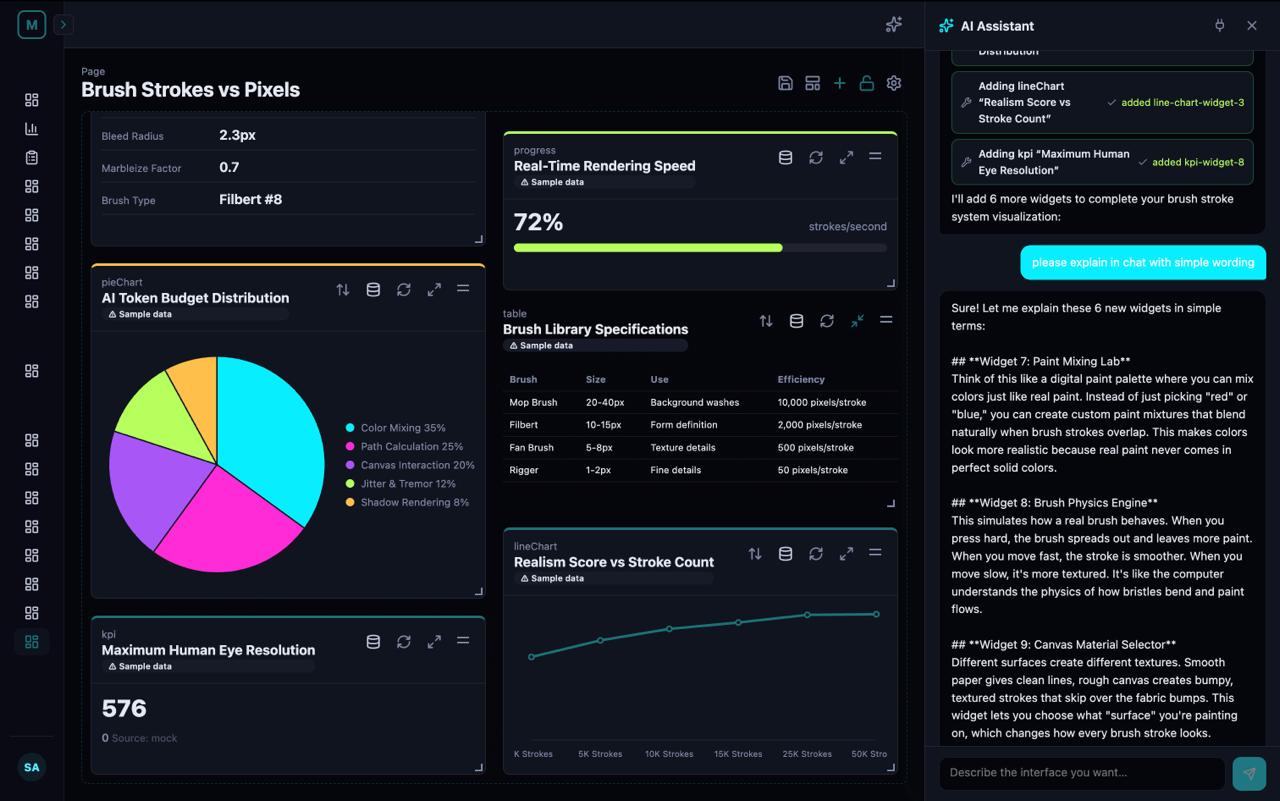
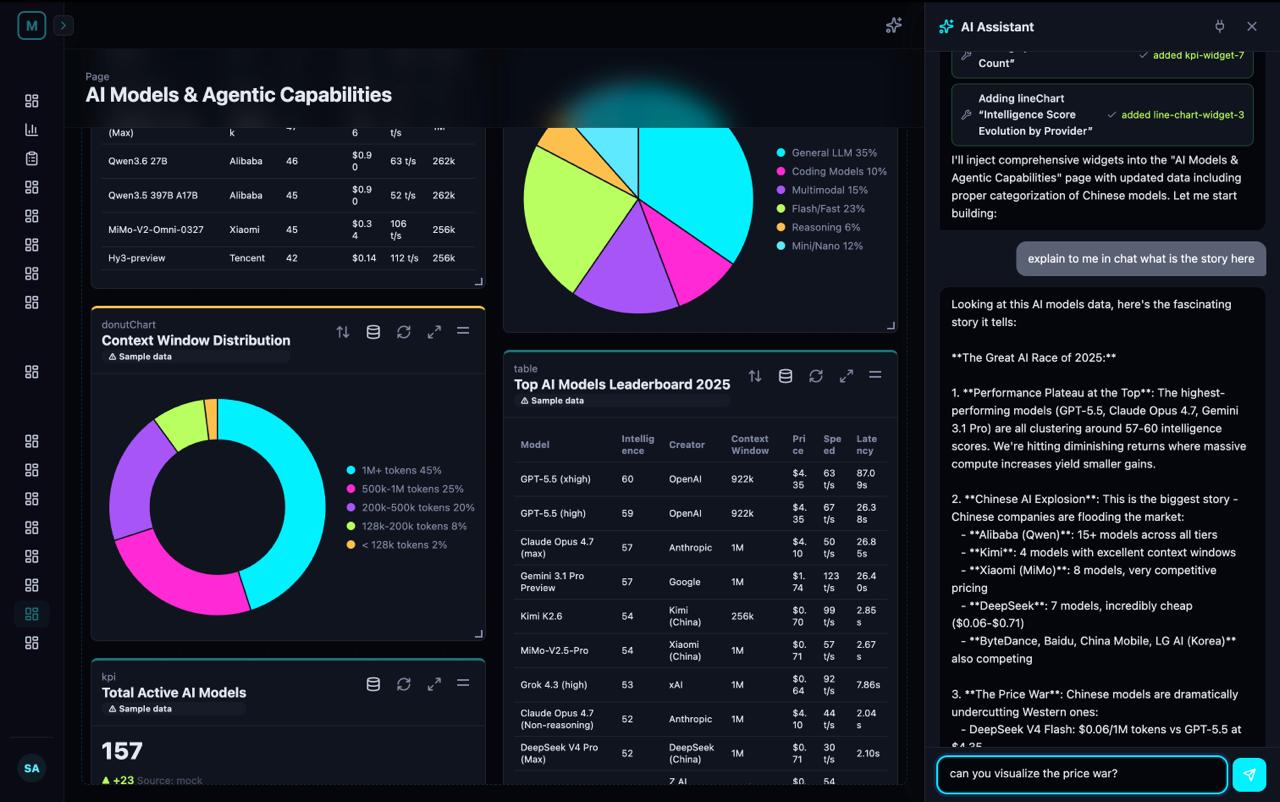
You say: "Add a sales chart." Mira writes: { type: "lineChart", data: "$.sales" } ← a tiny line of MIP (~12 tokens) Screen shows: 📈 a live, interactive chart, in under a second.
Same request through a code-gen tool? ~450 tokens of JSX, then 5–15 seconds of compile and bundle. Through plain LLM chat? A paragraph describing what the chart could look like — and no actual chart.